超详细Flink Source总结 |
您所在的位置:网站首页 › flink fromelement › 超详细Flink Source总结 |
超详细Flink Source总结
|
Flink Source flink 支持从文件、socket、集合中读取数据。同时也提供了一些接口类和抽象类来支撑实现自定义Source。因此,总体来说,Flink Source 大致可以分为四大类。 基于本地集合的source(Collection-based-source)基于文件的source (File-based-source)基于socket的source (Socket-based-source)自定义的source (Custom-source)另一方面,Flink也内置了许多常用的Source,例如FlinkKafkaConsumer。这些内置的Source可以帮助我们快速的实现自己的Source。 7.1 基于本地集合的sourceflink 主要提供两个基于本地获取数据的source: fromElements,fromCollection val env = StreamExecutionEnvironment.getExecutionEnvironment //0.用element创建DataStream(fromElements) val dataStream1: DataStream[String] = env.fromElements("spark", "flink") dataStream.print() //1.用Array创建DataStream val dataStream2: DataStream[String] = env.fromCollection(Array("spark", "flink")) dataStream.print()7.2 基于文件的sourceflink 对于文件的读取,也提供同样像readTextFile以及readFile等内置source。 readTextFile(path) 读取path 里所有的text文件,line-by-line and returns them as strings DataStream text = env.readTextFile("file:///path/to/file");readFile(fileInputFormat, path), 根据fileInputFormat格式读取一次文件// 外层父级目录 val dir = "file:///path"; val path = new Path(dir); val configuration = new Configuration(); // 设置递归获取文件 configuration.setBoolean("recursive.file.enumeration", true); val textInputFormat = new TextInputFormat(path); textInputFormat.supportsMultiPaths(); textInputFormat.configure(configuration); textInputFormat.setFilesFilter(new FilePathFilter() { @Override def boolean filterPath(Path filePath) { // 过滤想要的路径 !filePath.toString().contains("2021-11-04"); } }); env.readFile(textInputFormat,dir) readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo):这是上面两个方法内部调用的方法。它根据给定的 fileInputFormat 和path读取路径读取文件。根据提供的 watchType,这个 source 可以定期(每隔 interval 毫秒)监测给定路径的新数据(FileProcessingMode.PROCESS_CONTINUOUSLY),或者处理一次路径对应文件的数据并退出(FileProcessingMode.PROCESS_ONCE)。你可以通过 pathFilter 进一步排除掉需要处理的文件。DataStream stream = env.readFile(myFormat, myFilePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 100,FilePathFilter.createDefaultFilter(), typeInfo); 如果 watchType 设置为 FileProcessingMode.PROCESS_CONTINUOUSLY,则当文件被修改时,其内容将被重新处理。这会打破“exactly-once”语义,因为在文件末尾附加数据将导致其所有内容被重新处理。 如果 watchType 设置为 FileProcessingMode.PROCESS_ONCE,则 source 仅扫描路径一次然后退出,而不等待 reader 完成文件内容的读取。当然 reader 会继续阅读,直到读取所有的文件内容。关闭 source 后就不会再有检查点。这可能导致节点故障后的恢复速度较慢,因为该作业将从最后一个检查点恢复读取。 7.3 基于Socket的source 7.3 基于Socket的sourceenv.socketTextStream通过指定端口和host可以实现基于socket的监听。代码如下: val env = StreamExecutionEnvironment.getExecutionEnvironment val text = env.socketTextStream("localhost", 9999)7.4 自定义SourceFlink 提供了多个类接口,来支撑实现自定义source。 SourceFunction: 对所有StreamSource的顶层接口,直接继承该接口的Source无法将并行度设置大于1 /** * 当Source运行时就会调用run方法,结束时调用cancel */ class MyNonParallelSource extends SourceFunction[Access]{ private var isRunning = true override def run(ctx: SourceFunction.SourceContext[Access]): Unit = { val domains = List("flink.com", "spark.com", "mp.csdn.net") val random = new Random() while (isRunning) { val time = System.currentTimeMillis() + "" val domain = domains(random.nextInt(domains.length)) val flow = random.nextInt(10000) 1.to(10).map(x => ctx.collect(Access(time, domain, flow))) } } override def cancel(): Unit = { isRunning = false } } //自定义生成数据,并行度不能被设置超过1 val ds = env.addSource(new MyNonParallelSource)RichSourceFunction: implements SourceFunction,同时 extends AbstractRichFunction。支撑Source 全生命周期控制,如 open(),close()。 ParallelSourceFunction:ParallelSourceFunction继承了SourceFunction接口,它并没有定义其他额外的方法,仅仅是用接口名来表达意图,即可以被并行执行的stream data source(继承该接口的实例能够将并行度设置大于1)。 class MyParallelSource extends ParallelSourceFunction[Access] { private var isRunning = true override def run(ctx: SourceFunction.SourceContext[Access]): Unit = { val domains = List("flink.com", "spark.com", "mp.csdn.net") val random = new Random() while (isRunning) { val time = System.currentTimeMillis() + "" val domain = domains(random.nextInt(domains.length)) val flow = random.nextInt(10000) 1.to(10).map(x => ctx.collect(Access(time, domain, flow))) } } override def cancel(): Unit = { isRunning = false } } //自定义生成数据,并行度能被设置大于1 val ds2 = env.addSource(new MyParallelSource)RichParallelSourceFunction:实现了ParallelSourceFunction接口,同时继承了AbstractRichFunction,所以可以支撑自定义Open,Close 函数。 /** * MySQL作为FLink的Source */ class MySQLSource extends RichParallelSourceFunction[City]{ private var conn:Connection = _ private var state:PreparedStatement = _ override def open(parameters: Configuration): Unit = { val url = "jdbc:mysql://localhost:3306/g7" val user = "user" val password = "password" conn = MySQLUtil.getConnection(url,user,password) } override def close(): Unit = { MySQLUtil.close(conn,state) } override def run(ctx: SourceFunction.SourceContext[City]): Unit = { val sql = "select * from table_test" state = conn.prepareStatement(sql) val rs = state.executeQuery() while(rs.next()){ val id = rs.getInt(1) val name = rs.getString(2) val area = rs.getString(3) ctx.collect(City(id,name,area)) } } override def cancel(): Unit = {} } //自定义从MySQL中取出数据,支持并行度大于1 val ds3 = env.addSource(new MySQLSource)几个Source 关联图如下: 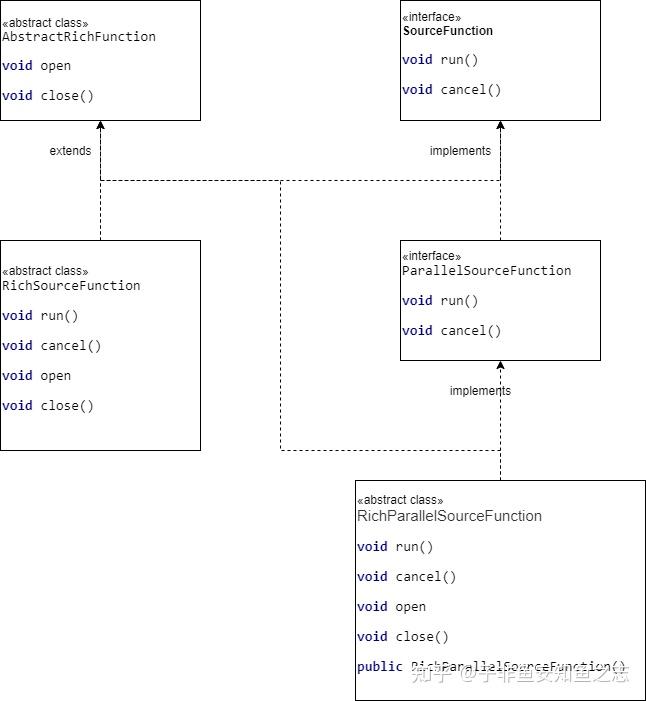 7.5 常用的内置Source(kafka) 7.5 常用的内置Source(kafka)FlinkKafkaConsumer(官方链接:FlinkKafka)。 Flink 的 Kafka consumer 称为 FlinkKafkaConsumer。它提供对一个或多个 Kafka topics 的访问。 构造函数接受以下参数: Topic 名称或者名称列表 用于反序列化 Kafka 数据的 DeserializationSchema 或者 KafkaDeserializationSchema Kafka 消费者的属性。需要以下属性: “bootstrap.servers”(以逗号分隔的 Kafka broker 列表) “group.id” 消费组 ID import java.util import java.util.Properties import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer object KafkaTryJob { def main(args: Array[String]) { val env = StreamExecutionEnvironment.getExecutionEnvironment // 初始化 Kafka 配置 val properties = new Properties() properties.setProperty("bootstrap.servers", "localhost:9092") properties.setProperty("group.id", "flink-group-id") import org.apache.flink.api.scala._ // 单个topic // val stream = env // .addSource(new FlinkKafkaConsumer[String]("topic", new SimpleStringSchema(), properties)) // 多个topic val topics = new util.LinkedList[String] topics.add("topic1") topics.add("topic2") val mySource = new FlinkKafkaConsumer[String](topics, new SimpleStringSchema(), properties) // 可以配置kafka消费的起始位置 mySource.setStartFromEarliest(); // 尽可能从最早的记录开始 //mySource.setStartFromLatest(); // 从最新的记录开始 //mySource.setStartFromTimestamp(...); // 从指定的时间开始(毫秒) //mySource.setStartFromGroupOffsets(); // 默认的方法 val stream = env .addSource(mySource) env.execute("kafka-try-job") } } |
【本文地址】